Navigating the Complex Multi-Cloud World with Ease

According to the State of the Cloud Report for 2021, 92 percent of businesses have a multi-cloud strategy in place, while 82 percent have a hybrid cloud strategy. Today, multi-cloud is the default state of corporate technology, whether by accident or design. As cloud adoption grows, companies are realizing that a one-size-fits-all strategy will not fulfill their business objectives. Organizations are relying on a range of IaaS, PaaS, and SaaS offerings to supply the cost-effective and adaptable applications needed for agile and creative operations. They are also likely to be running private cloud or on-premises infrastructures at the same time.
There are many compelling reasons to run your infrastructure across several clouds, from guaranteeing availability and resilience to moving workloads to achieve maximum efficiency, cost savings, or avoiding vendor lock-in.
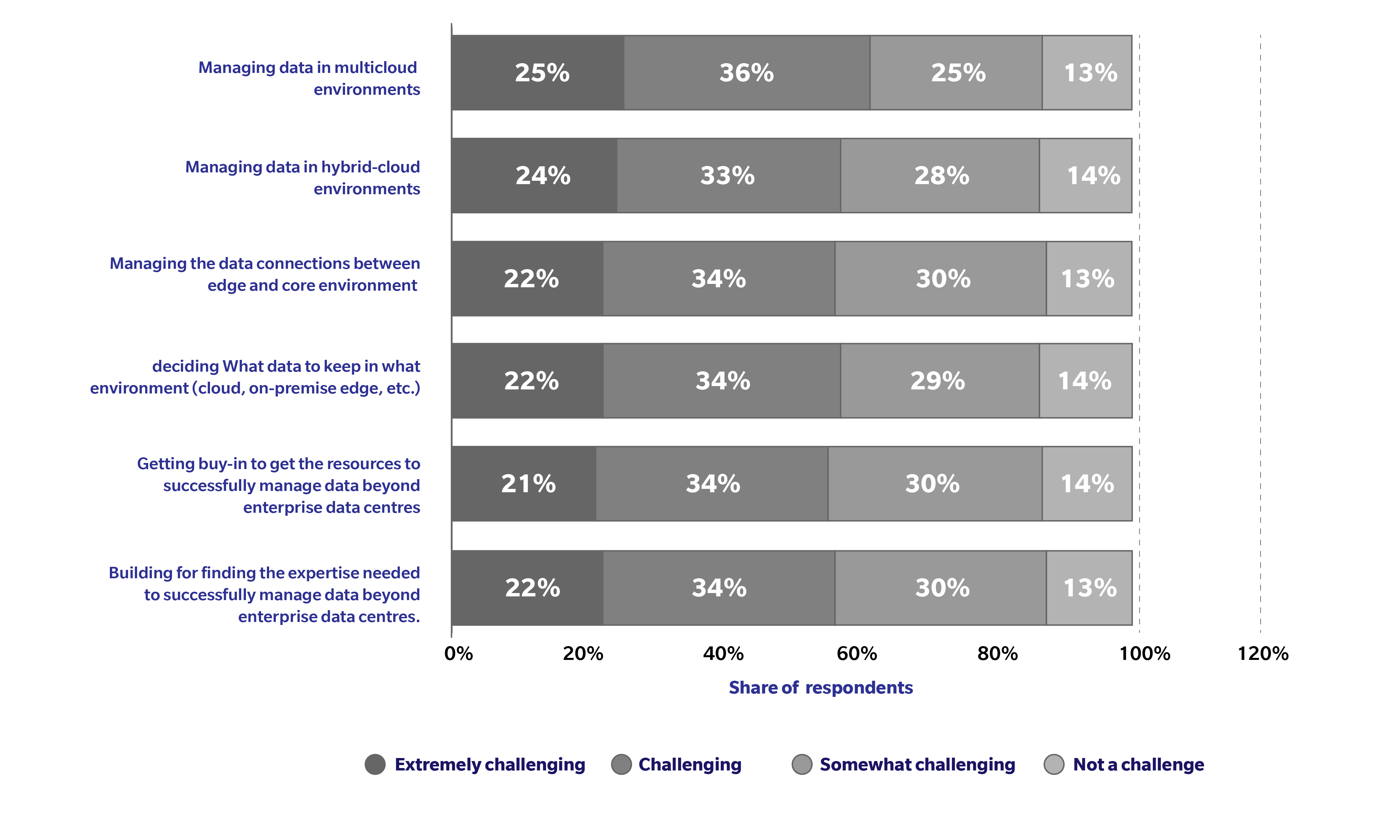
But on the other side, there are some challenges which you might encounter from a data perspective while adopting a multi-cloud architecture. The chart below shows how challenging will it be for your enterprise to manage data in more than one cloud.
Let’s dive into the challenges which your data warehouse and lakes might face in a multi-cloud environment.
Data Challenges in a Highly Distributed Multi-Cloud World
Moving to the cloud doesn’t address the data management problems that come with digital transformation. Your company’s data is spread across on-premises systems as well as public and private clouds, thanks to ever-increasing data quantities. This leads to additional data silos, making it more difficult to integrate, convert, manage, and sync all of that heterogeneous data promptly to make it relevant to your business. Most companies today face common problems related to accessibility, integration, visibility, security, and data governance when they engage with numerous cloud service providers.
Architectural Integration
Applications are distributed over several clouds, therefore, the new architecture must ensure that the underlying data is interoperable and flows easily between them, regardless of where it is stored (on-premise, public or private cloud). This necessitates the use of cloud data in conjunction with cloud-native ELT and ETL. Data storage methods and databases, as well as data lake selections, can all play a part in guaranteeing data portability.
Security & Risk Mitigation
There is no one point of control to monitor security and compliance in a multi-cloud environment, making it difficult for enterprises to monitor and safeguard different systems. While core architectural services for data backup, discovery, protection, replication, and restoration are being built across different cloud environments, capabilities for cloning data, masking specific components, and securely storing duplicated data should also be established. This can help you build a genuinely agile company that offers more apps and services more seamlessly and safely.
Accessibility and Visibility
Data fragmentation puts settings at risk by generating data silos that are difficult to manage and maintain. Data availability must be ensured, regardless of where it sits or the complexity required in accessing that data and its provenance – understanding where your data comes from and how it is changed at every step of the data pipeline.
Organizations are plagued by the lack of visibility across divisions or regions when they install various clouds. Furthermore, without a central console, companies struggle to obtain information or expertise about cost, setup, use, and performance in a multi-cloud environment.
Data Governance & Compliance
Cloud-based IT platforms, which are highly scalable, shared, and automated, can disguise the physical location of data from both the client and the service provider. This may result in regulatory infractions.
Furthermore, data handling requirements in bigger data-driven businesses are frequently complicated. For example, distinct subsets of client data may need to be delivered to separate teams, in different apps, in different formats, all with varying service level needs or specifications.
Consider what would happen if the data of these several teams were stored in different clouds. You can imagine the level of intricacies such a situation may produce. Organizations must account for these issues in the new multi-cloud environment, and comprehensive data management must be included as one of the essential fundamental elements in their design.
Lack of an Effective Data Strategy
When constructing or upgrading a data warehouse, it’s important to have a well-thought-out data strategy. Without a data strategy, it would not only be difficult for diverse teams to adapt to the new data warehouse, but it will also be hard to realize all the benefits of a data warehouse. This necessitates collaboration among stakeholders, which is why development, design, and planning must all be part of a single continuous process.
How Rawcubes empowers Data-Driven Transformation in a Multi-Cloud Ecosystem?
DataBlaze enables organizations to effectively manage the issues of scattered and fragmented data, allowing them to innovate using their data across any platform, cloud, multi-cloud, and hybrid environments. This is one of the most complete end-to-end data management solutions available since it is cloud-native and AI-powered. You can catalog, ingest, integrate, prep, cleanse, master, and share all of your data, no matter where it is, process it however you want, ensure it is trusted and democratized on a governance foundation, and deliver intelligent insights with a 360-degree view of your business with our intelligence services.
Get comprehensive insight into your data and navigate the multi-cloud ecosystem seamlessly with Rawcubes.